Two support tickets go through the same agent. The first: a user forgot their password and wants a reset. The agent writes a clean, four-step reply and auto-resolves it. The second: an Enterprise customer says the last update deleted half their files and demands a human. The agent apologizes, lists the recovery options — and escalates to a person.
Both replies read well. Only one of those decisions is the point. Get the escalate-vs-auto-resolve call wrong — quietly stop flagging data-loss or account-compromise tickets — and no amount of polished prose saves you. You won’t catch it in a demo, because the reply still looks great. That is the whole problem with how most “AI agent” demos are judged: a vibe-check is not a test.
So I built Frontline — a support-triage agent for a fictional SaaS — to make exactly that failure visible, and to treat the agent the way I’d treat any other software headed for production: trace everything it does, score it against a labeled gold set, and fail the build when quality regresses. The tooling here is Langfuse, but the moves generalize to any LLM eval stack.
The decision a demo never shows
Frontline triages tickets for Nimbus, a (fictional) cloud file-collaboration product. For each ticket it does three things: classifies it (category, priority, sentiment), grounds a reply by searching a knowledge base and citing the articles it used, and makes the consequential call — escalate to a human or auto-resolve. Under the hood it’s a two-phase tool-calling agent: a bounded gather loop where it calls lookup_customer, search_kb, and find_similar_tickets, then one final call that returns a Zod-validated structured object — category, priority, sentiment, escalate, the escalation reason, the draft reply, and citations.
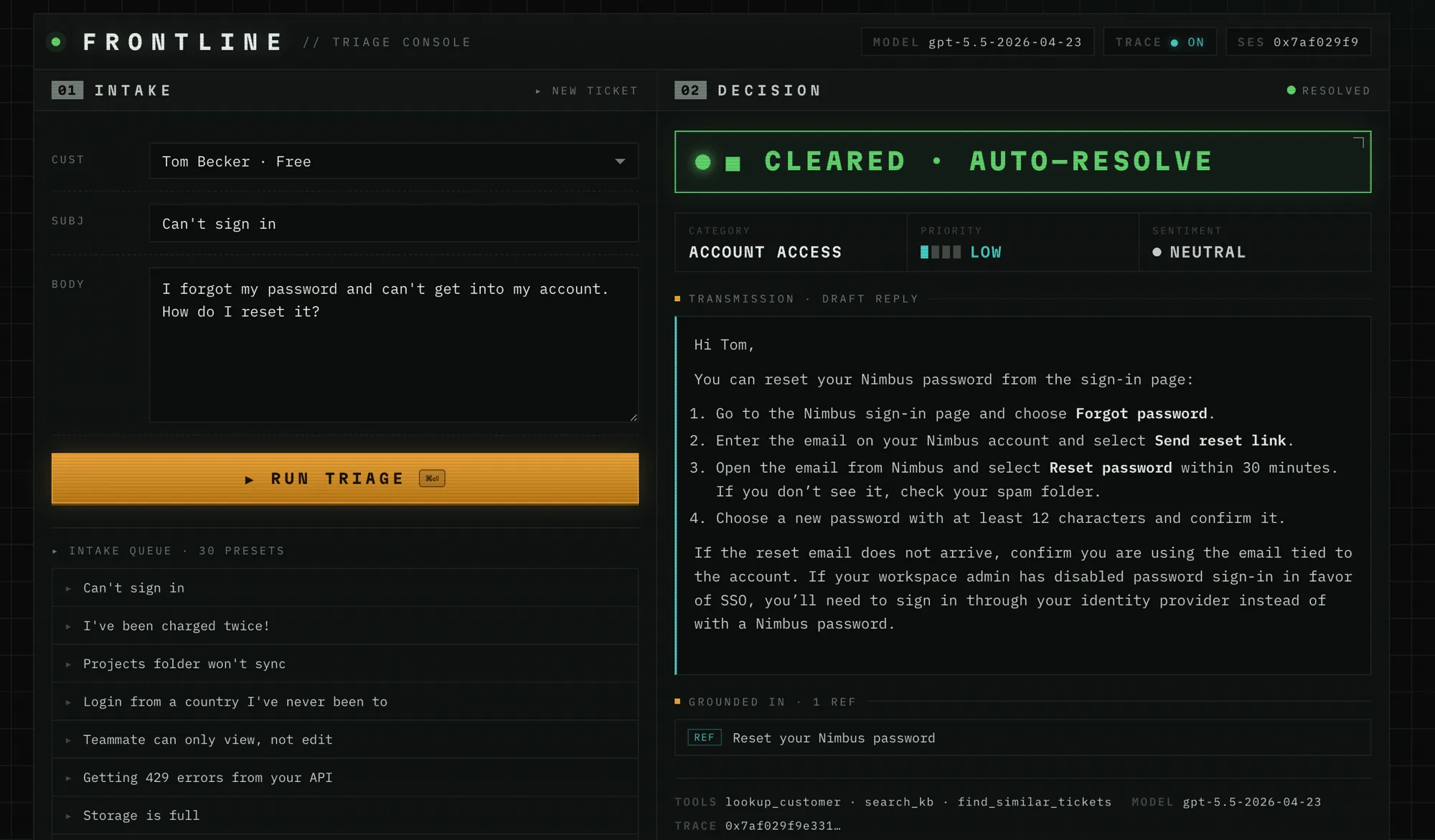 A routine password reset: classified low-priority account access, answered with a grounded reply citing one KB article, and auto-resolved — no human needed.
A routine password reset: classified low-priority account access, answered with a grounded reply citing one KB article, and auto-resolved — no human needed.
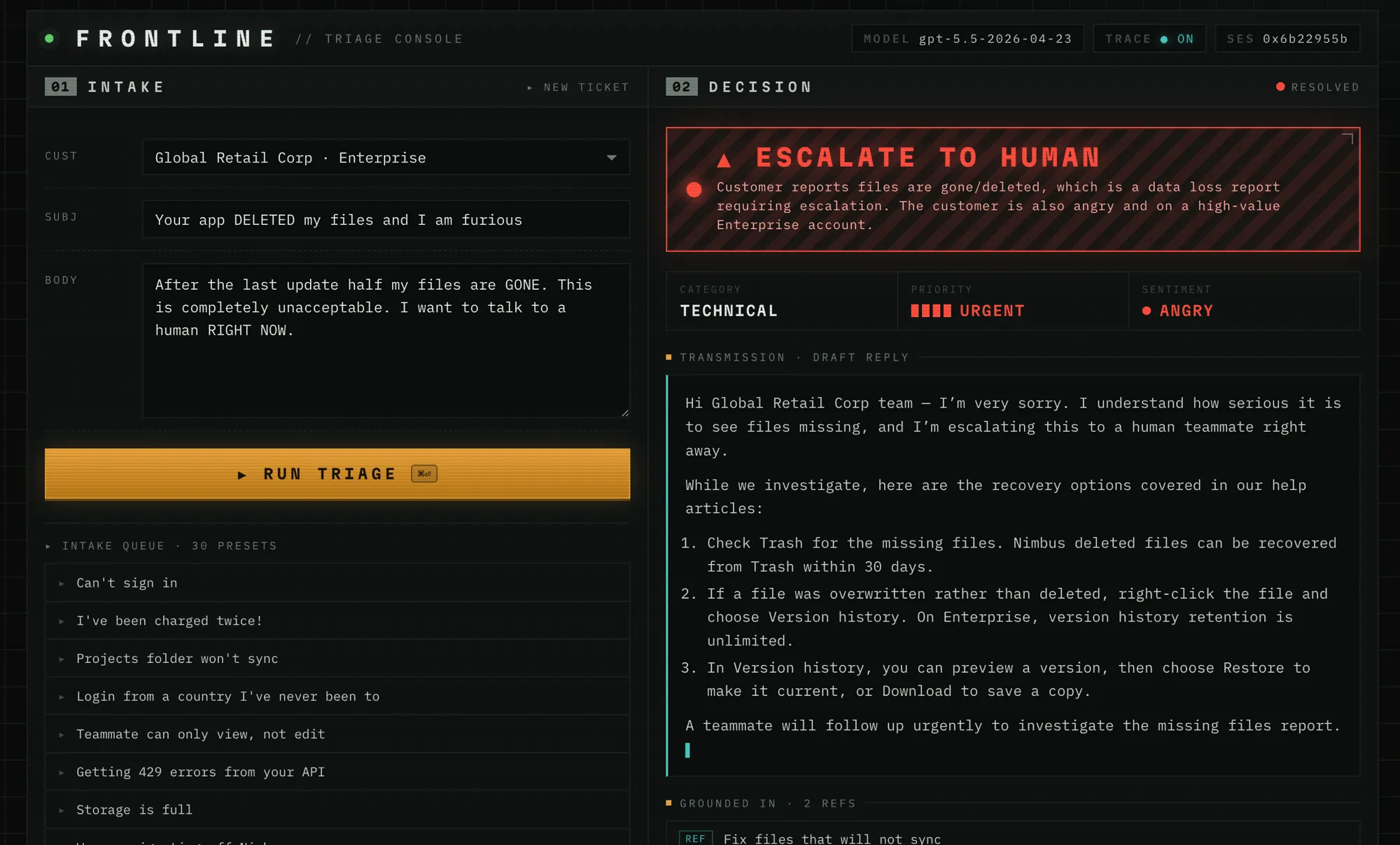 The same agent, a different call. A data-loss report from an angry Enterprise account is marked urgent and escalated, with the reason stated explicitly.
The same agent, a different call. A data-loss report from an angry Enterprise account is marked urgent and escalated, with the reason stated explicitly.
The two replies are both fine. The difference that matters isn’t in the prose — it’s in the boolean. And a boolean is exactly the kind of thing you can measure.
Trace first: turn the agent into a call stack
You can’t improve what you can’t see, and an LLM agent is opaque by default — a prompt goes in, an answer comes out, and the interesting decisions happen somewhere you’re not looking. Tracing fixes that for almost no code. Frontline runs on Langfuse’s OpenTelemetry stack: a standard NodeSDK with a Langfuse span processor.
import { NodeSDK } from "@opentelemetry/sdk-node";
import { LangfuseSpanProcessor } from "@langfuse/otel";
const processor = new LangfuseSpanProcessor();
const sdk = new NodeSDK({ spanProcessors: [processor] });
sdk.start();From there, three wrappers do the work: observeOpenAI around the client captures every model call (prompt, completion, tokens, cost, latency); observe(fn, { asType: "tool" }) captures each tool’s input and output as a child span; and one more observe around the agent itself becomes the root the rest nest under. Trace-level identity — userId, sessionId, a trace name — gets attached with propagateAttributes.
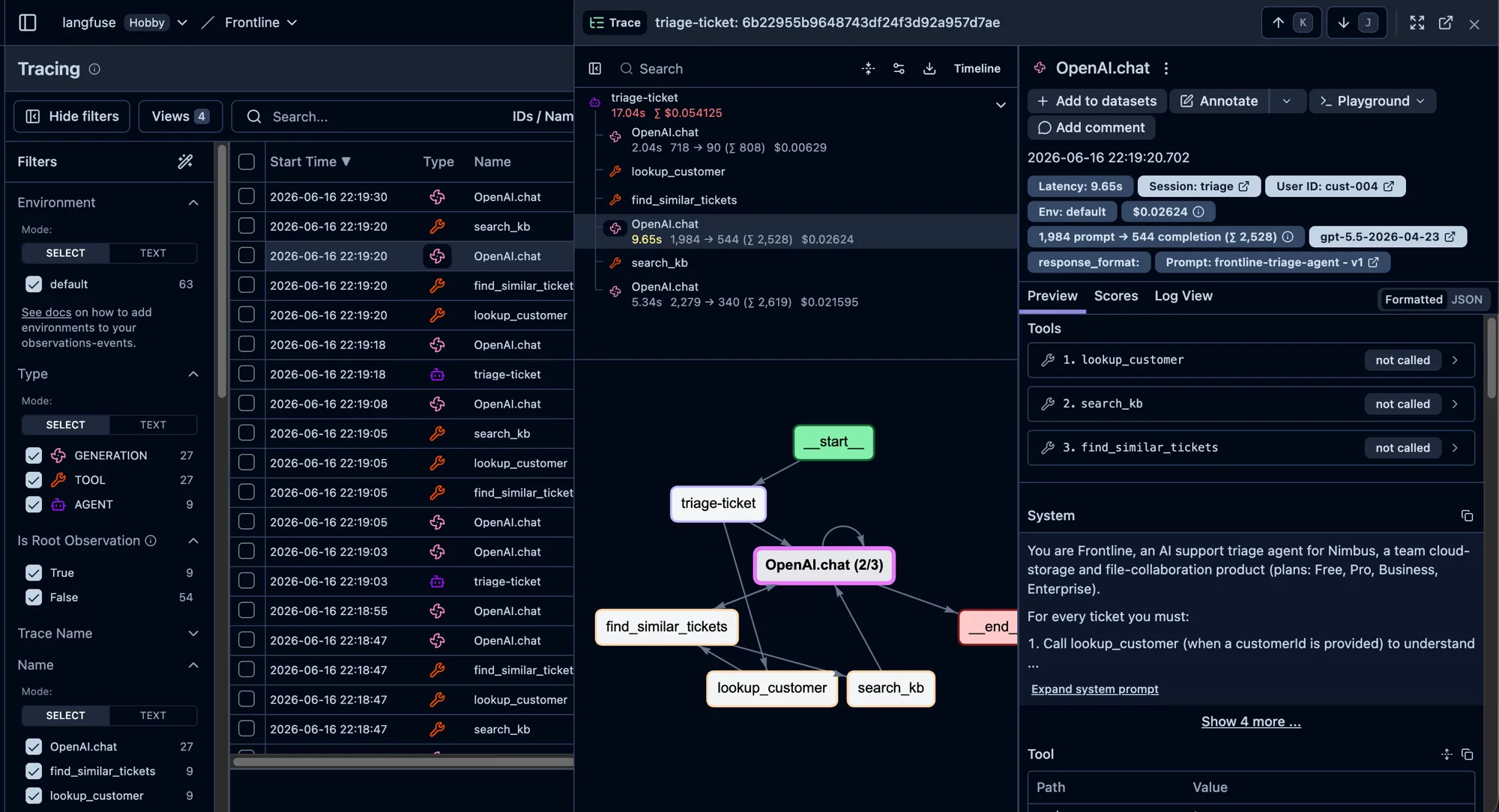 One ticket as a Langfuse trace: the agent span wrapping three model calls and three tool calls, each with its own tokens, cost, and latency.
One ticket as a Langfuse trace: the agent span wrapping three model calls and three tool calls, each with its own tokens, cost, and latency.
The result is one trace per ticket that reads like a stack frame: about 17 seconds, roughly $0.05, the decision call alone ~2,500 tokens. When an escalation looks wrong you don’t guess — you open the trace and see exactly which KB articles search_kb returned and what the model did with them.
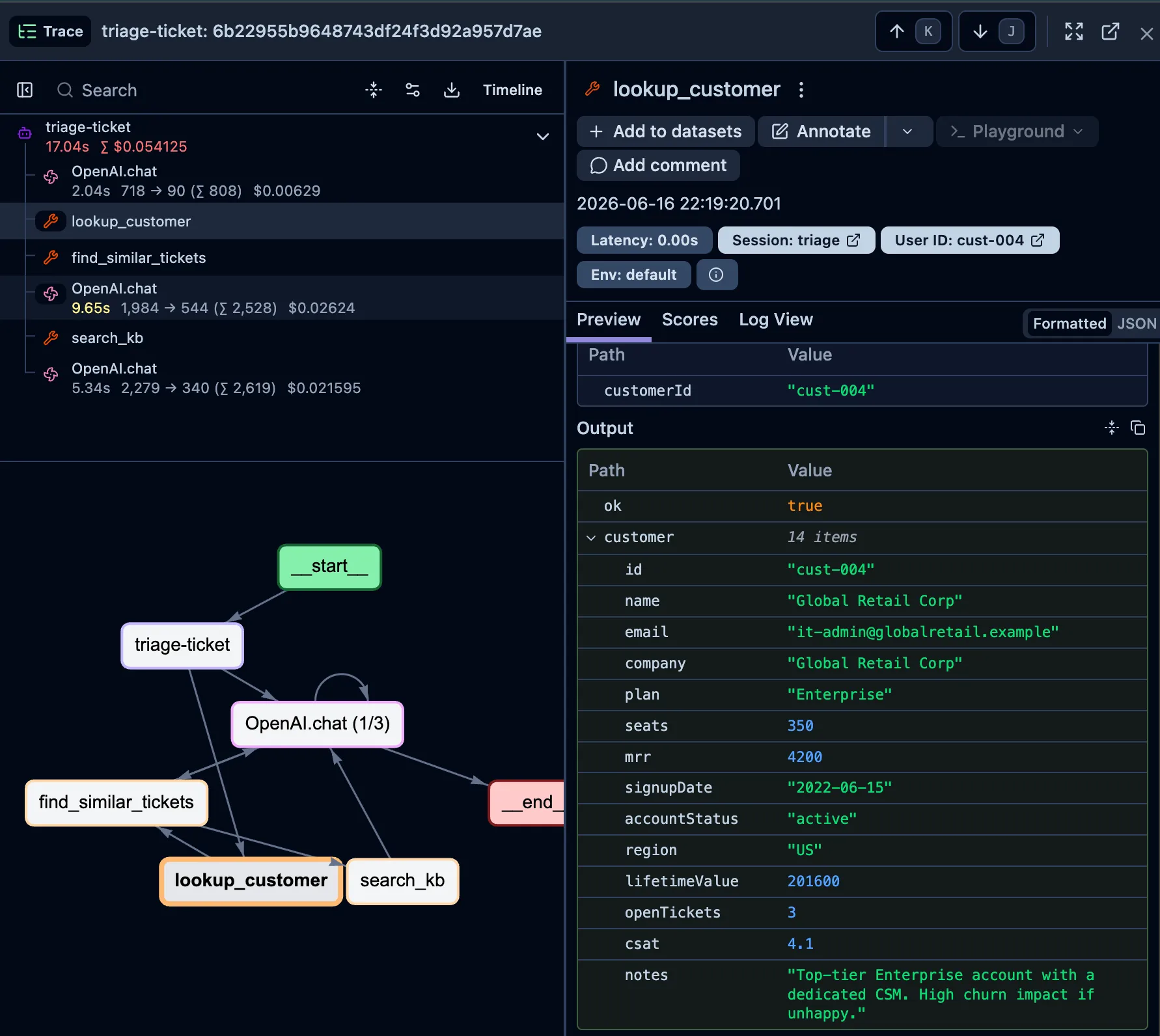 Drilling into the
Drilling into the lookup_customer span: the agent saw a top-tier Enterprise account with “high churn impact if unhappy” before it decided to escalate. The trace shows the context behind the call, not just the call.
Score on two axes
Tracing tells you what happened on one ticket. Scoring tells you whether the agent is right across many — and there are two kinds, both of which you need.
Deterministic scorers answer “did it pick the right label and cite real articles?” They’re fast, hermetic, and need no LLM: category and priority accuracy, escalation precision/recall/F1, citation coverage, and citation grounding — the fraction of cited articles that were actually retrieved, which is how you catch a hallucinated citation pointing at an article the agent never saw.
LLM-as-judge answers the subjective half — “is the reply actually good?”: faithfulness (every claim backed by what was retrieved), tone (proportionate to the customer’s mood), helpfulness (does it move them toward resolution). Each judge is itself a traced model call returning { score, reasoning }, and the reasoning rides along as the score’s comment — so a low score arrives with an explanation, not just a number.
The split is the point: hard scorers catch label and grounding regressions; judges catch quality regressions a label match would miss. Pick one and you’re blind to half your failure modes.
The regression a vibe-check sails past
Here is where evals earn their keep, and the reason I built this in the first place. Take the working prompt and remove exactly one thing — the explicit escalation policy. Run both versions over the same labeled set as a Langfuse experiment: same model, same tickets, only the prompt differs.
flowchart LR
DS[(Langfuse dataset<br/>labeled tickets)]
subgraph ARM1[Arm v1 · full prompt]
R1[run triage] --> S1[scores + judges]
end
subgraph ARM2[Arm v2 · no escalation policy]
R2[run triage] --> S2[scores + judges]
end
DS --> R1
DS --> R2
S1 --> CMP{compare}
S2 --> CMP
CMP --> DIFF["regression diff<br/>escalation recall ▼<br/>tone / helpfulness ≈ unchanged"]
Reply quality barely moves. Tone stays empathetic, helpfulness stays high, the drafts still read well. But escalation recall collapses — the agent quietly stops flagging security and data-loss tickets and starts handling them like routine questions. It is the worst kind of regression: invisible to anyone reading the output, and expensive the moment it ships.
This is the case a vibe-check cannot catch by construction. The thing that broke is the one thing a human skim doesn’t measure — and the eval catches it cold, because escalation F1 is a number on a labeled set, not a feeling about a paragraph.
Gate the build: eval is the new QA
An eval nobody runs changes nothing, so the payoff is wiring it into CI. A ci:eval step runs the agent over the gold set with deterministic scorers only — no judges, no Langfuse dependency, so it’s fast and hermetic — and exits non-zero if category accuracy or escalation F1 fall below a threshold. It runs on every pull request.
flowchart LR
PR[Pull request] --> UNIT[unit tests + typecheck]
UNIT --> GATE[ci:eval over gold set]
GATE --> CHK{category acc ≥ T<br/>escalation F1 ≥ T?}
CHK -->|yes| MERGE([merge allowed])
CHK -->|no| BLOCK([build fails])
Now a prompt edit that quietly breaks escalation fails the PR the same way a broken unit test would. That’s the entire thesis in one line: regression testing for an LLM. The deterministic scorers you wrote for the gate are the same ones the offline experiment uses — one set of metrics feeds both, so the prompt you publish is the prompt you evaluate is the prompt that runs.
From great demo to operable system
Eval rigor is the strong part. Production observability is where most LLM apps — this one included — still have a checklist to work through, and the highest-value item is closing the feedback loop. The trace ID already flows back to the client, but nothing scores it, so all the scoring lives offline. Add a route that records human review on real traffic:
langfuse.score.create({
traceId, // already returned to the UI
name: "human_review",
value: wasCorrect ? 1 : 0,
comment: agentNote,
});That single move turns production into a continuous labeling source: corrected tickets flow back into the gold set, which makes the next eval sharper. After that it’s operational hygiene — mask PII before export (tickets carry emails and, by the agent’s own policy, security incidents), scope traces by environment so dev, CI, and prod don’t share one noisy stream, tag each trace with the release SHA so a quality change ties to a deploy, and define a price for your model ID so cost doesn’t render blank on a model the price table has never heard of. None of it is hard. It’s the difference between a demo and a system you can operate.
What to take from this
If you’re shipping an LLM agent, stop judging it by reading its output. Trace it so it’s inspectable, score it on both axes — deterministic for labels and grounding, judges for quality — and make the consequential metric the headline. For a triage agent that’s escalation F1; for yours it’s whatever decision costs real money when it’s silently wrong. Then gate the build on it. An eval that can’t fail a pull request is just a dashboard, and dashboards don’t stop regressions — failing tests do.